Masked Autoencoders Are Scalable Vision Learners
论文地址:https://arxiv.org/pdf/2111.06377。
作者:何凯明
机构: Facebook
摘要
带掩码的自编码器是一个可拓展的视觉学习器
MAE基于两个核心设计,可以高效的训练大模型:
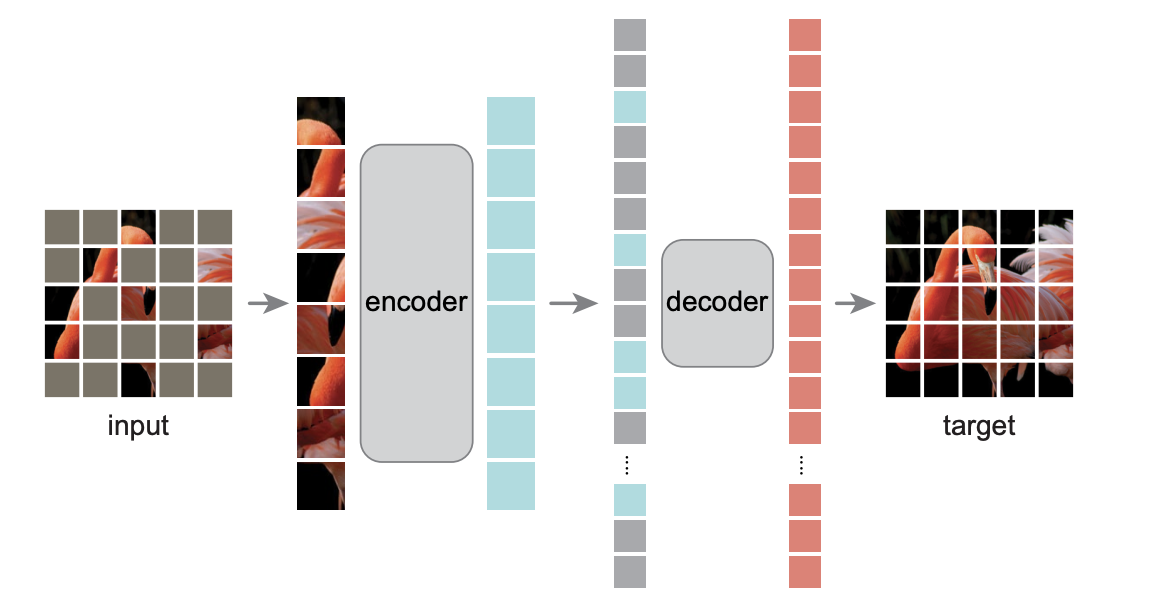
1、非对称的encoder-decoder架构编码器只作用在可见的patch中,对于丢掉的patch,编码器不会对它进行编码,这样能够节省一定的计算时间。解码器是一个比较轻量的解码器,拿到编码器的输出之后,重构被遮挡住的块。
2、使用较高的mask比例将mask比例设置为75%,迫使模型得到一个较好的自监督训练效果。如果只是遮住几块的话,只需要进行插值就可以出来了,模型可能学不到特别的东西。编码器只编码1/4大小的图片,可以降低计算量,训练加速3倍或者以上模型结构。最终作者只使用一个最简单的ViT-Huge模型(模型结构来自ViT这篇文章),在ImageNet-1K(100万张图片)上预训练,准确率能达到87.8%;这个模型主要是用来做迁移学习,它证明了在迁移学习的其他任务上表现也非常好注:在ViT这篇文章的最后一段有提到过怎样做自监督学习,作者说效果并不是很好,结论是:用有标号的模型和大的训练集可以得到很好的效果。本文亮点是,只使用小的数据集(ImageNet-1k,100万张图片),而且是通过自监督,就能够做到跟之前可能效果一样好的模型了。
网络结构